
|| 山っぽい形のデータの分布
「だいたいのデータが従う分布」のこと
スポンサーリンク
目次
正規分布「平均と分散の型が決まってる分布」
正規分布の母数「母平均と母分散の確認」
単純な分布への近似「二項分布に寄せた成果が正規分布」
確率化「得られた形を確率的に扱えるように加工する」
標準正規分布「平均も分散も単純になってるやつ」
正規分布 Normal Distribution
|| よく見られる代表的なデータの分布
「平均 μ 」と「分散 σ^2 」に従う分布で
\begin{array}{lcr} N(μ,σ^2) && 正規分布 \\ \\ N(0,1) && 標準正規分布 \end{array}
「 \mathrm{Normal\,Distribution} 」の頭文字をとって
このように書かれることがあります。
\begin{array}{ccc} f(x) &=& \displaystyle \frac{1}{\sqrt{2πσ^2}}\exp{\left(-\frac{(x-μ)^2}{2σ^2}\right)} \end{array}
またこれの『確率密度関数 f 』はこうです。
(この式の意味がわからないと感じるのは正常)
よく見られるデータの偏り
「測量」や「天体観測」のデータ
「二項分布のヒストグラム」など
\begin{array}{ccc} よくある形 & \left\{ \begin{array}{lcl} 中央が盛り上がってる \\ \\ 左右対称な形をしてる \\ \\ 左右に遠くなるとほぼ0になる \end{array} \right. \end{array}
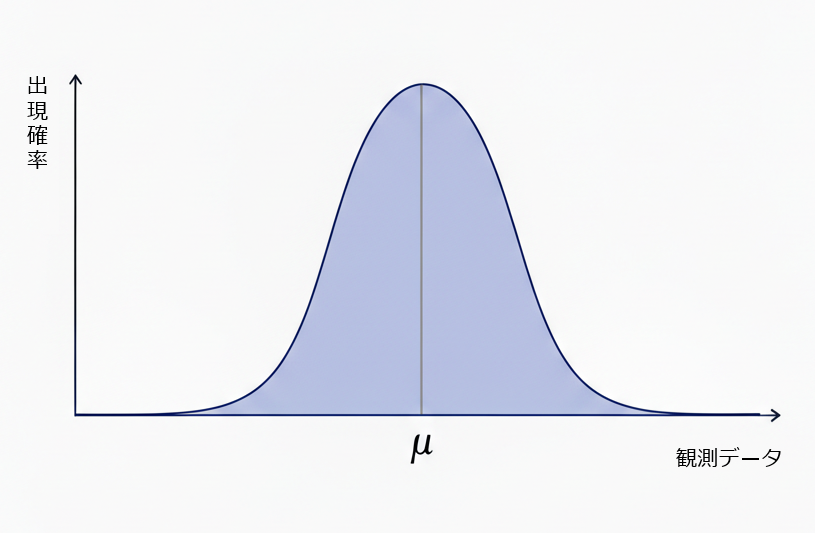
昔から統計的にこういった形は得られていて
\begin{array}{lcl} よく見る &\to& 多項式やらいろいろ試す \\ \\ 指数関数の試行 &\to& 結果的に実データとほぼ一致 \\ \\ &\to& 中心付近の丸みが丁度良い \\ \\ &\to& 指数なので左右の低下速度が速い \end{array}
これをうまい具合に数式で表現したものが
\begin{array}{lcl} 実データの観察 &\to& 特定の図形的な性質が分かる \\ \\ &\to& その性質を満たす式を探す \\ \\ &\to& 多項式関数や指数関数を試す \\ \\ &\to& 結果的にe^{-x^2}が良い感じだった \\ \\ \\ 事後的整理 &\to& 生成関数や中心極限定理 \\ \\ &\to& 数式的な正当化が可能になった \\ \\ &\to& 標準的な分布として定着した \end{array}
「正規分布」と呼ばれるものになります。
(つまり要請を都合よく満たしたものがあの複雑な式)
図形的な要請と指数関数
改めて整理すると
\begin{array}{ccc} よくある形 & \left\{ \begin{array}{lcl} 中央が盛り上がってる \\ \\ 左右対称な形をしてる \\ \\ 左右に遠くなるとほぼ0になる \end{array} \right. \end{array}
まず『正規分布の原型への要請』はこうです。
(この時点では『現実の数式による記述』が目的)
\begin{array}{lcl} 形の要請 &\to& いろんな関数の図を観察 \\ \\ &\to& まず単純な関数を調べる \\ \\ \\ 左右対称 &\to& xと-xのyが一致 \\ \\ &\to& x^2や|x|を使えば実現可能 \\ \\ \\ 山っぽい形 &\to& 0から+へ行くと急激に下がる \\ \\ &\to& 減少するタイプの関数と予想可能 \\ \\ \\ 端でほぼ0 &\to& 常に正の関数が理想的 \\ \\ &\to& \displaystyle \frac{1}{x}や\frac{1}{a^x}が候補に挙がる \end{array}
なので『発想される式の形』は
\begin{array}{l} コーシー分布の原型 && \displaystyle \frac{1}{x} &\to & \displaystyle \frac{1}{x^2} &\to& \displaystyle \frac{1}{1+x^{2}} \\ \\ ラプラス分布の原型 && \displaystyle \frac{1}{a^{x} } &\to& \displaystyle \frac{1}{a^{|x|}} &\to& \displaystyle \frac{1}{ e^{|x|} } \end{array}
「単純なもの」だとこのようなものが想定されます。
(山のような形で左右対称であるという要請から)
高精度化の要請
以上の候補を改めて整理すると
\begin{array}{ccc} \displaystyle \frac{1}{x} & \overset{対称に}{\to} & \displaystyle \frac{1}{|x|} & \overset{曲線的に}{\to} & \displaystyle \frac{1}{x^2} & \overset{0の整備}{\to} & \displaystyle \frac{1}{1+x^2} \end{array}
こういった「曲線的な感覚」により
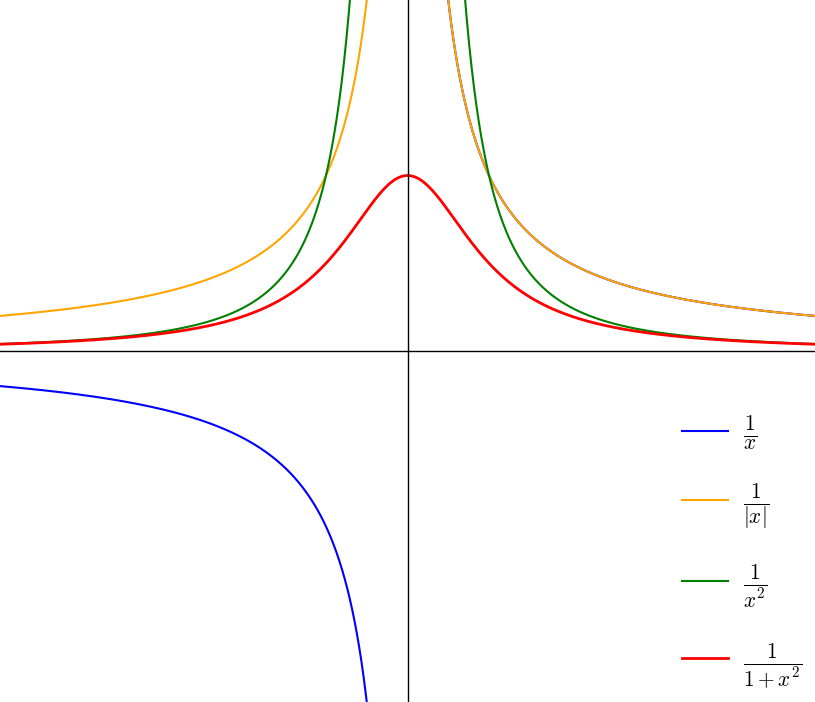
『実際のデータに近い』という意味で
「高精度化される」のは
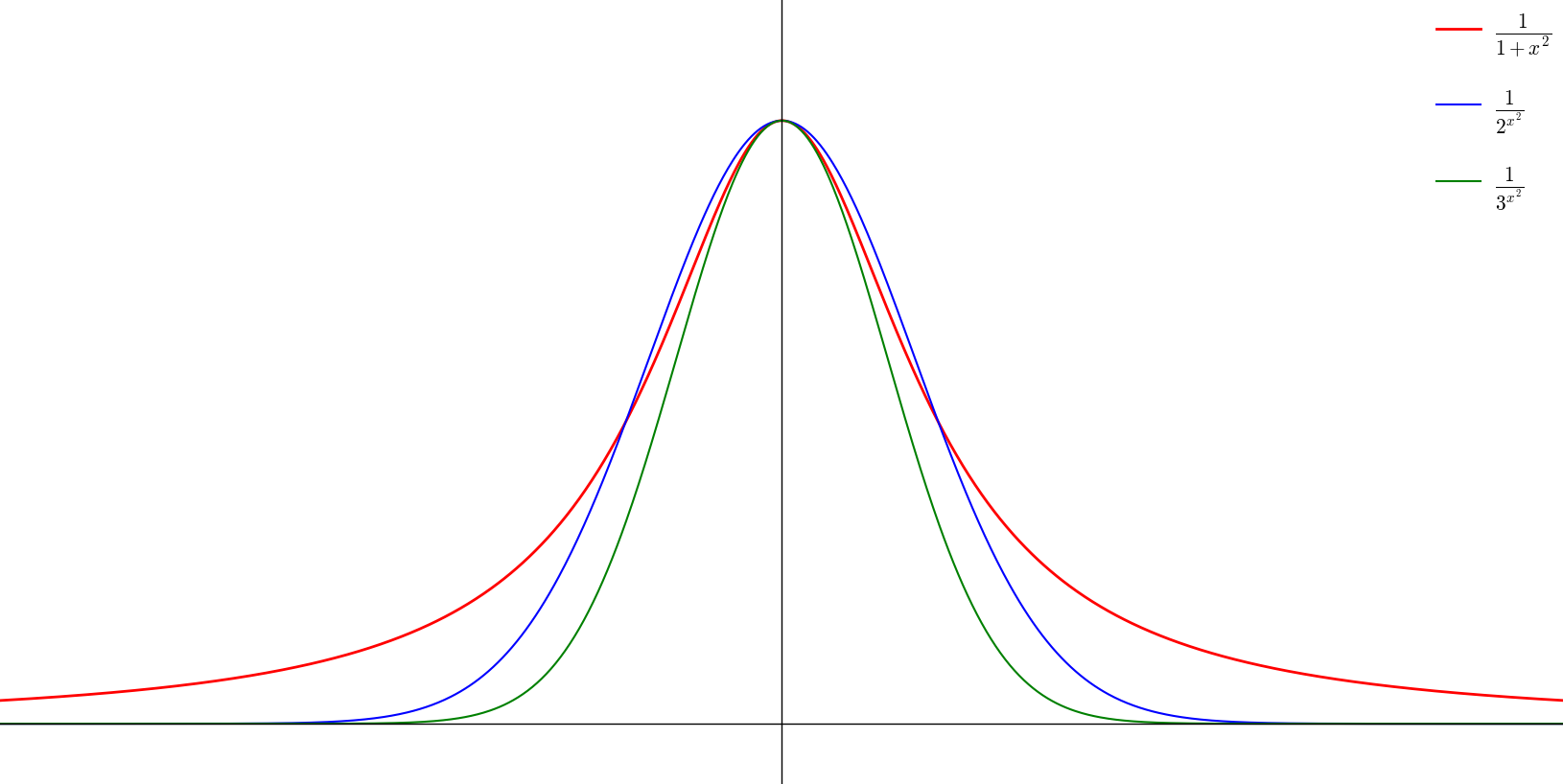
\begin{array}{ccc} \displaystyle \frac{1}{a^x} & \overset{対称に}{\to} & \displaystyle \frac{1}{ a^{|x|} } & \overset{曲線的に}{\to} & \displaystyle \frac{1}{ a^{x^2} } & \overset{単純に}{\to} & \displaystyle \frac{1}{ e^{x^2} } \end{array}
『例外はほぼ出ない』という要請と
(中央の近く以外はほぼ 0 になる)
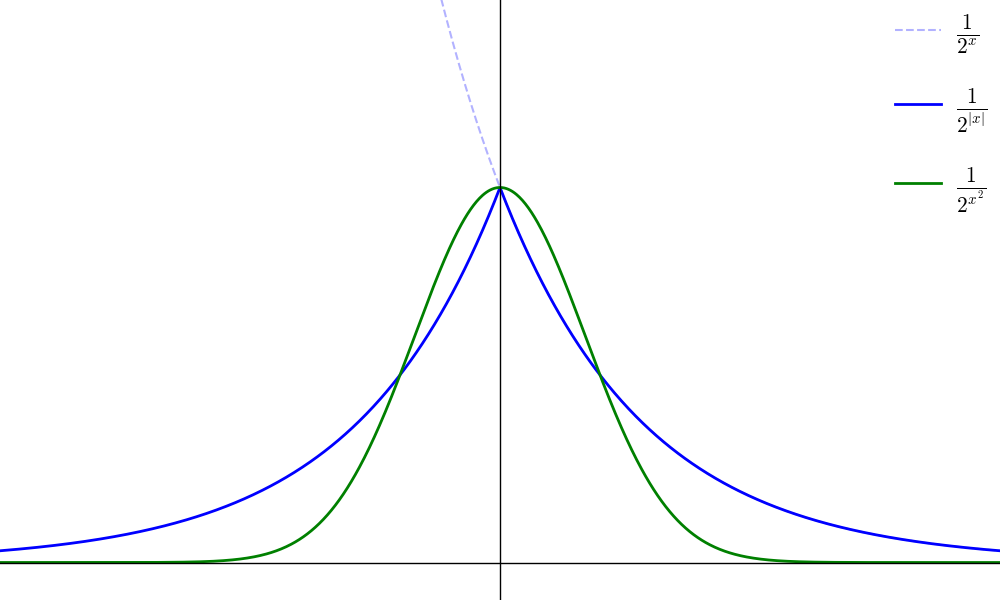
『図形の観察から』明らかです。
(実際のデータの分布に近いのが 1/a^{x^2} の形)
整理すると
\begin{array}{lcl} 図形要請 &\to& 右と左で下がる形 \\ \\ &\to& 逆数なんかが使える \\ \\ &\to& 全体的な形は対称的にしたい \\ \\ &\to& |x|とかx^2が使える \\ \\ &\to& 図形中央の観察で比較 \\ \\ &\to& x^2の形の方が実際に近い \\ \\ &\to& 分母が0になるのは避けたい \\ \\ &\to& x^2に1を足す形を分母とする \\ \\ \\ 例外要請 &\to& 単純な形は例外の部分で不一致 \\ \\ &\to& 中央付近以外はほぼ0になる \\ \\ &\to& 高次関数や指数関数を試行 \\ \\ &\to& 実際の図形に近くなる \\ \\ &\to& 指数関数の方が扱いやすさで優位 \\ \\ &\to& データの形とほぼ一致した \end{array}
要請による絞り込みの流れはこんな感じ。
(現実のデータとの比較から絞り込まれる)
対応範囲の拡張要請
「平均値」を使った『 x 軸での平行移動』要請と
(どのような平均値にも対応できるようにする)
\begin{array}{lcc} x&\to& x-μ \\ \\ x^2 &\to& \displaystyle \frac{x^2}{σ^2} \end{array}
「分散」を使った『 y 軸の伸縮』要請
(分散は横に広がる感じの指標であると考える)
\begin{array}{ccc} \displaystyle e^{-\frac{(x-μ)^2}{2σ^2}}&=& \displaystyle \exp{\left(-\frac{(x-μ)^2}{2σ^2}\right)} \end{array}
これらによって結果的に得られたのがこの形で
(この構成のためにはまだ要請が不足している)
\begin{array}{lcl} 図形の位置 &\to& 左右対称なので中心は平均値 \\ \\ &\to& 平均値で中心を決める \\ \\ &\to& xがμと一致する時に0になる \\ \\ \\ 図形の形 &\to& 尖ってたり平たくなったり \\ \\ &\to& 分散は平均からの遠さの指標 \\ \\ \\ 分散の活用 &\to& 図形の広がりに対応する \\ \\ &\to& 分散が小さければ尖る \\ \\ &\to& 分散が大きければ広がる \\ \\ \\ どう使う? &\to& 全体 e^{-x^2} への作用だと比率が変わるだけ \\ \\ &\to& 拡大縮小は起きるが形はそのまま \\ \\ &\to& x^2なら引き延ばしと収縮が起きる \\ \\ &\to& x^2への作用なら尖りと膨れを実現可能 \end{array}
その要請の詳細はこんな感じになっています。
(この時点ではまだ不明な部分がある)
実際のデータと二項分布
以上と『実際のデータとの比較』から
\begin{array}{lcl} 比較したい &\to& 実際のデータはいろいろある \\ \\ &\to& シンプルなのが望ましい \\ \\ \\ 単純なデータ &\to& 規則的であることが望ましい \\ \\ &\to& 結果が少ない方が望ましい \\ \\ \\ 最小の分岐 &\to& 2通りの結果のみが最小 \\ \\ &\to& コインの裏表や出る出ないなど \\ \\ &\to& n回行うベルヌーイ試行 \\ \\ \\ 規則的なもの &\to& 全ての事象が分かるのが理想 \\ \\ &\to& 二項分布が候補の最有力に \end{array}
この要請として導かれたのが
「全事象が分かっている二項分布」で
\begin{array}{lcl} 期待値 &\to& np \\ \\ 分散 &\to& npq \end{array}
これは「母数(パラメータ)」が分かることから
\begin{array}{ccc} \displaystyle \frac{1}{e^{x^2}} &\overset{中心の調整}{\to}& \displaystyle \frac{1}{e^{ (x-μ)^2} } &\overset{形の調整}{\to}& ? \end{array}
『一致させる指標』として機能してくれます。
(この時点では指標の1つに過ぎない)
全事象が分かっている二項分布
改めて整理しておくと
\begin{array}{ccc} コイン &\left\{ \begin{array}{lcl} 1回試行 &\to& 表か裏 \\ \\ 2回試行 &\to& 表表,表裏,裏表,裏裏 \\ \\ &\vdots \end{array} \right. \end{array}
これは要はこういう話なので
(試行回数 n 回で事象は必ず 2^n 個になる)
\begin{array}{ccc} n=1 &&\to && E[X] &=& \displaystyle 1\cdot \frac{1}{2} +0\cdot \left( 1-\frac{1}{2} \right) \\ \\ && \to && E[X] &=& \displaystyle \frac{1}{2} \\ \\ \\ n=1 &&\to && E[X] &=& 1\cdot p+0\cdot (1-p) \\ \\ && \to && E[X] &=& p \end{array}
「期待値 E[X]=μ 」は必ずこのようになります。
(表や出るなどが 1 でそうじゃないなら 0 )
\begin{array}{ccl} V[X] &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-μ)^2p_i \\ \\ &=& \displaystyle \left( \frac{1}{n} \sum_{i=1}^{n} x_i^2p_i \right) - \left( \frac{1}{n} \sum_{i=1}^{n} 2μx_ip_i \right) +\left( \frac{1}{n} \sum_{i=1}^{n} μ^2p_i \right) \\ \\ &=& \displaystyle \left( \frac{1}{n} \sum_{i=1}^{n} x_i^2p_i \right) - μ^2 \end{array}
また「期待値」が分かることから
\begin{array}{ccc} n=1 &&\to && V[X] &=& \displaystyle \left(1^2\cdot \frac{1}{2} +0^2\cdot \left( 1-\frac{1}{2} \right) \right) - \left( \frac{1}{2} \right)^2 \\ \\ && \to && V[X] &=& \displaystyle \frac{1}{2} \left( 1-\frac{1}{2} \right) \\ \\ \\ n=1 &&\to && V[X] &=& \Bigl( 1^2\cdot p+0^2\cdot (1-p) \Bigr) -p^2 \\ \\ && \to && E[X] &=& p(1-p) \end{array}
「分散」もまた確定させることができます。
(全事象が確定しているので全体の母数が分かる)
n 回試行の全事象が分かる二項分布
この「二項分布」では「独立同分布である」という
(全て同じ確率とする「同様に確からしい」も)
\begin{array}{ll} 定義後 & \left\{ \begin{array}{lcl} 独立 &\to& 共通部分を持たない \\ \\ &\to& X∩Y≠∅ \\ \\ &\to& 前の結果は後に影響しない \\ \\ &\to& P(A|B)P(B)=P(A)P(B) \\ \\ &\to& 前と後は別々に考えられる \\ \\ &\to& X∩Y≠∅ ⇒E[X∪Y]=E[X]+E[Y] \\ \\ \\ 同分布 &\to& 同じ全体を切り分けてる \\ \\ &\to& 全体=表+裏(例外排除) \\ \\ &\to& 1 = \displaystyle \sum_{i=1}^{n} p_i \end{array} \right. \end{array}
「余計な要素が排除された」形の
(厳密には「シンプルな分布の特徴」が独立同分布)
\begin{array}{lcl} 実際 & \left\{ \begin{array}{lcl} 整理前 &\to& 独立同分布ではない \\ \\ 整理後 &\to& 独立同分布に近づく \\ \\ 定義後 &\to& 独立同分布とする \end{array} \right. \end{array}
『整理された状態』を前提にできるので
(正確には余計な例外を考えないことにした結果がこれ)
\begin{array}{lclcl} 全体 && P(X)&=&1 \\ \\ 切り分け && P(X)&=&P(X_1)+P(X_2)+\cdots + P(X_n) \end{array}
「 n 回の試行」はこのように表現できます。
(このシンプルな形を得るために同分布であると定義する)
\begin{array}{ccc} X∩Y≠∅ &\to& E[X∪Y]=E[X]+E[Y] \end{array}
そして「複数の試行の期待値 E[X∪Y] 」の定義から
(既存定義の定義改変がこちらの定義では不要になる)
\begin{array}{lcl} E[X] &=& E[X_1]+E[X_2]+\cdots + E[X_n] \\ \\ &=& p+p+\cdots +p \\ \\ &=& np \end{array}
「二項分布では」このようになり
(これはコインの表が出た回数などを意味する)
\begin{array}{ccl} V[X] &=& E \Bigl[ (X-E[X])^2 \Bigr] \\ \\ &=& E \Bigl[ (X_1-E[X_1])^2 \Bigr] +\cdots+E \Bigl[ (X_n-E[X_n])^2 \Bigr] \\ \\ &=& p(1-p)+p(1-p)+\cdots +p(1-p) \\ \\ &=& np(1-p) \end{array}
「分散」もまた同様に計算できます。
(分散は期待値によって定義されている)
整理された実データと良い形の関数
以上の事実を用いて調整していくと
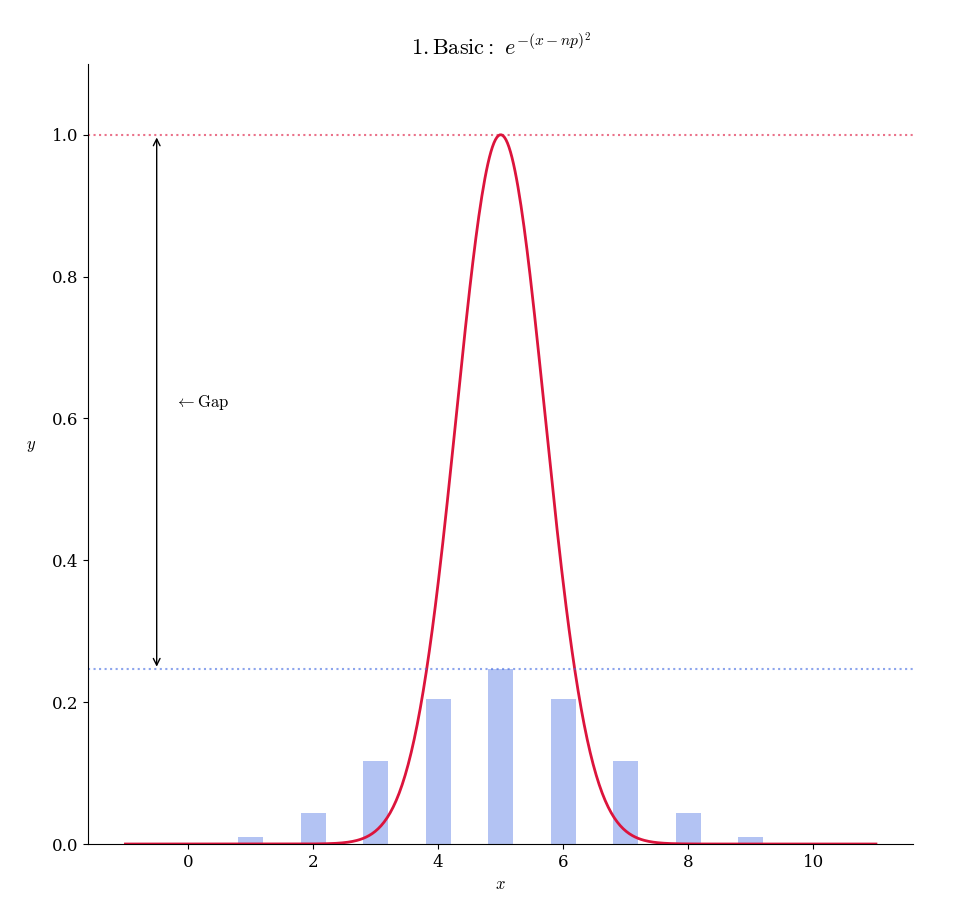
まずこの調整は
このような形で実現できます。
(二項分布の山頂を求めればいい)
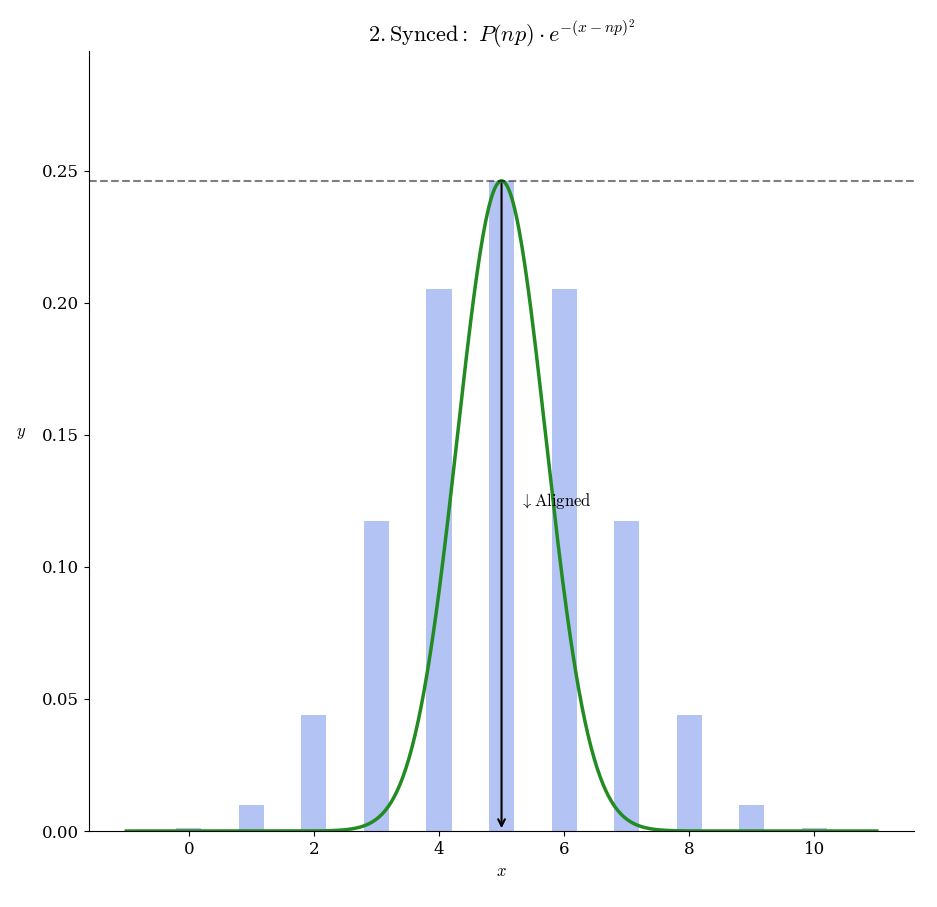
そして「分散の位置」については
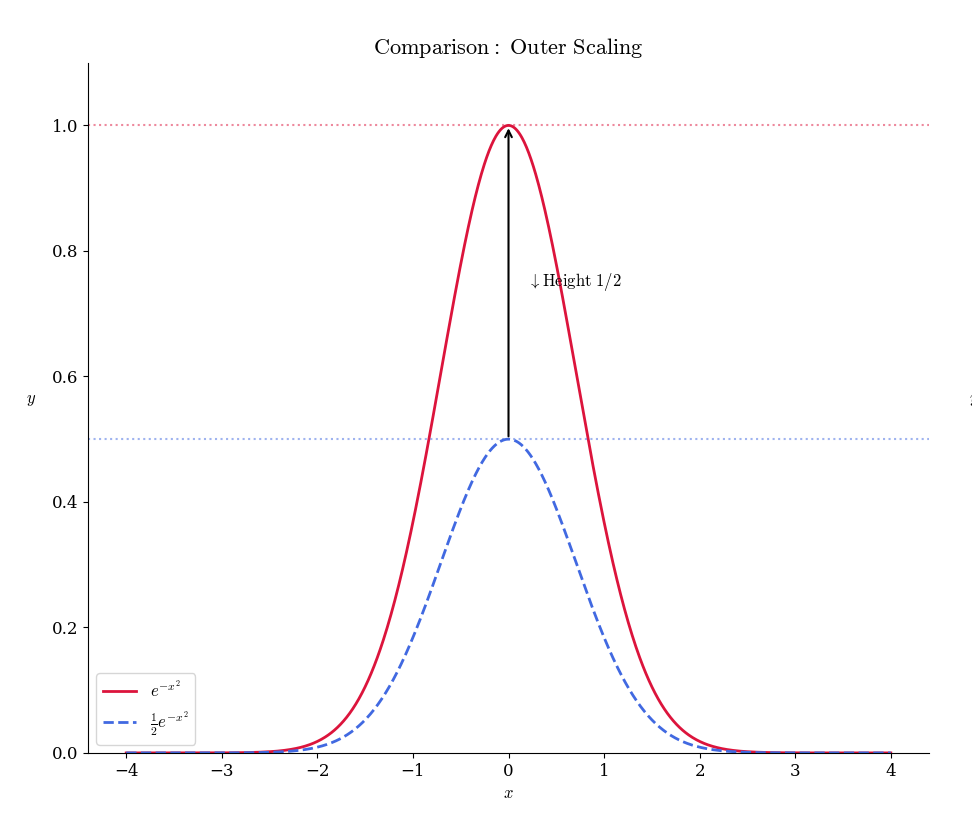
この「縦の伸縮操作」と
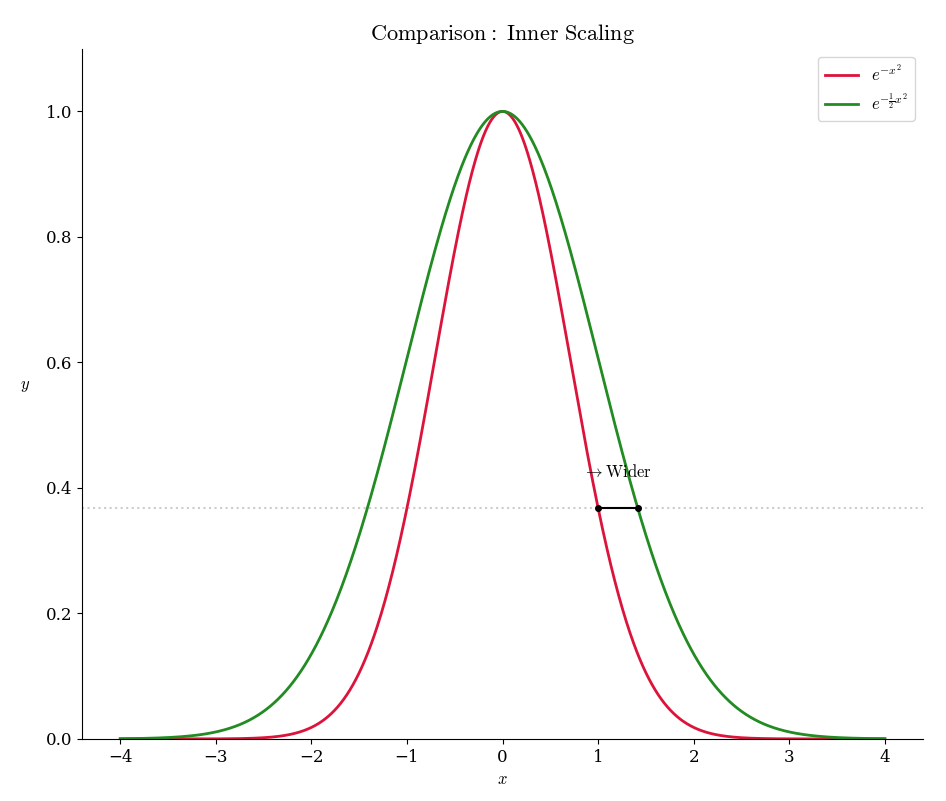
「横の伸縮操作」を比較すれば
この「両者を近づけたい」という要請から
\begin{array}{lcl} \displaystyle \frac{1}{e^{x^2}} & \overset{\displaystyle c\times \frac{1}{e^{x^2}} }{\longrightarrow} & 縦の伸縮 && 不要 \\ \\ \displaystyle \frac{1}{e^{x^2}} & \overset{\displaystyle c\times x^2 }{\longrightarrow} & 横の伸縮 && 必要 \end{array}
『横の伸縮操作が要請を満たす』と分かるので
\begin{array}{lcl} 分散が大きい &\to& 平均に寄らない &\to& 横に広い \\ \\ 分散が小さい &\to& 平均に寄る &\to& 尖ってる \end{array}
この「分散の意味」から
(そのままではなく逆数で考えるのが適切)
\begin{array}{ccc} \displaystyle P(np)\frac{1}{e^{ \frac{(x-μ)^2}{σ^2} } } &=& \displaystyle P(np)e^{\displaystyle - \frac{ (x-np)^2 }{np(1-p)}} \end{array}
このような形を得ることができます。
(かなり現代の正規分布の形に近づく)
補足しておくと
\begin{array}{lcl} P(0) &=& (1-p)^n \\ \\ P(np) &=& 山頂の確率 \end{array}
「二項分布の n 回試行の確率 P 」は
\begin{array}{ccc} P(k) &=& \displaystyle {}_n \mathrm{C}_{k} p^k (1-p)^{n-k} \end{array}
このような形で求めることができます。
(「表表裏」「表裏表」などの組み合せの数え上げです)
不一致と調整するための c
ただここまでやっても
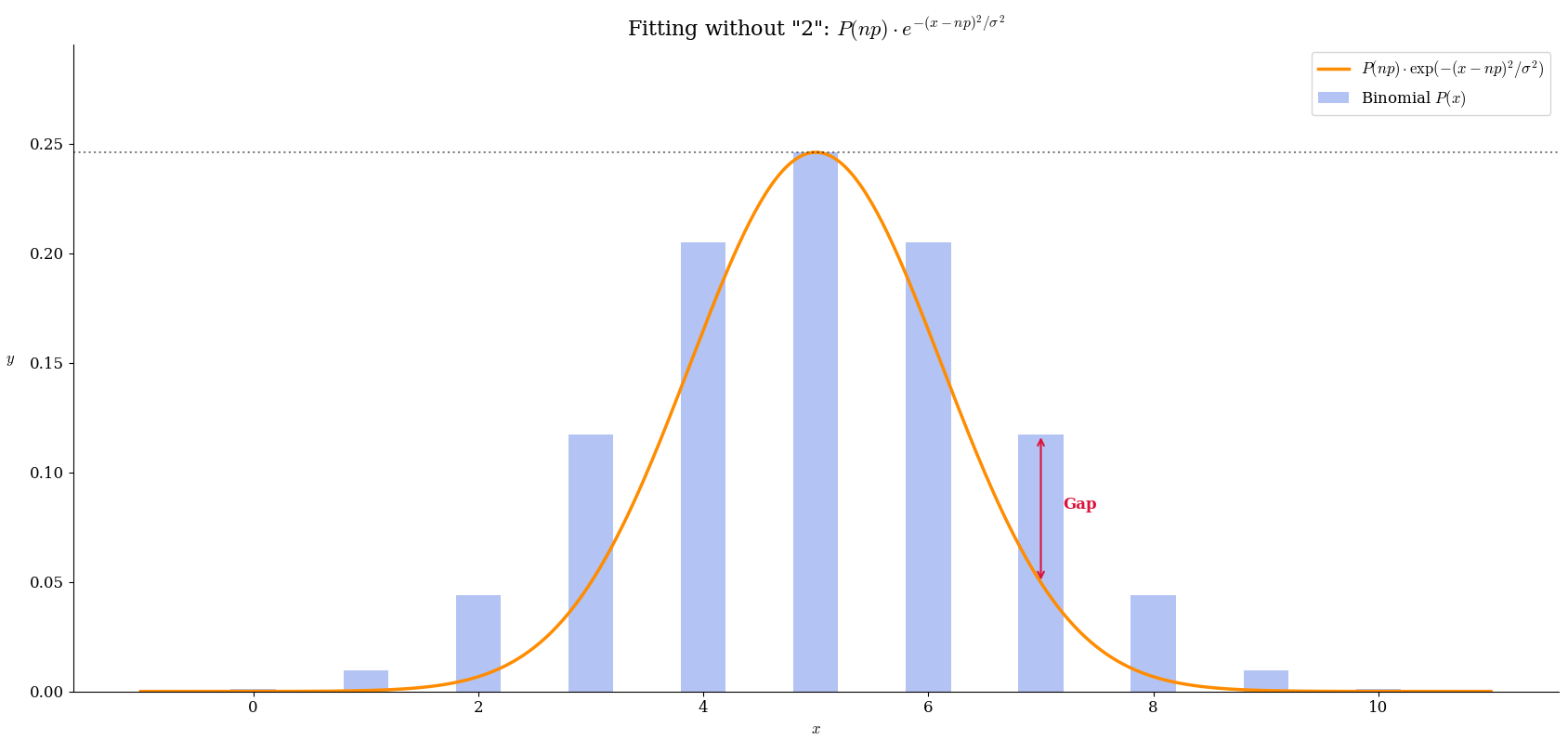
まだ『2つの図形は一致しない』ので
\begin{array}{lcl} 分散だけ &\to& 横の広がりが足りない \\ \\ &\to& 分散より大きい値が必要 \\ \\ &\to& 分散の他にx^2の分母の値が必要 \end{array}
『 x^2 の分母を大きくする』必要があります。
(この時点では実際のデータしか手掛かりがない)
ここで以下のような c を考えて
\begin{array}{lcl} N(x) &=& \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-μ)^2}{cσ^2} } \\ \\ &=& \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-np)^2}{cnp(1-p)} } \end{array}
「山頂の点以外」の点を得るために
\begin{array}{lcl} 横に広げたい &\to& 広げる基準が必要 \\ \\ &\to& 二項分布とN(x)の一致 \\ \\ &\to& x=a,y=bの二項分布を使う \\ \\ &\to& N(x)=bの時x=aとなるようなcが答え \end{array}
「最も単純な n=2,p=1/2 」のパターンで考えてみると
\begin{array}{lcl} \displaystyle p=\frac{1}{2} &\to& 表の回数の確率Pで考える \\ \\ &\to& \displaystyle P(0)=\frac{1}{4},P(1)=\frac{1}{2},P(2)=\frac{1}{4} \\ \\ &\to& \displaystyle μ=np=1, σ^2=np(1-p)=\frac{1}{2} \end{array}
「山頂 x=1 以外の点 x=0 」を考えた時
\begin{array}{lcl} x=0 &\to& \displaystyle y=P(0)=\frac{1}{4} \\ \\ x=0 &\to& \displaystyle y=N(0)=\frac{1}{4} \end{array}
このような関係が得られるので
\begin{array}{ccl} N(x) &=& \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-np)^2}{cnp(1-p)} } \\ \\ \displaystyle \frac{1}{4} &=& \displaystyle P(1) \cdot e^{\displaystyle -\frac{(0-1)^2}{c\frac{1}{2}} } &=& \displaystyle \frac{1}{2}\cdot\frac{1}{e^{\frac{2}{c}}} \end{array}
これはこのような式になり
\begin{array}{c} 2&=& e^{\frac{2}{c}} \\ \\ \log 2 &=& \displaystyle \frac{2}{c} \\ \\ c&=& \displaystyle\frac{2}{\log 2} &=& 2.885... \end{array}
求めたい調整値 c はこのようになります。
(この時点ではまだ c=2 にはならない)
n が増えると滑らかになっていく
ここから重要になるのが
\begin{array}{lcl} nが少ない &\to& 図形はギザギザ \\ \\ nが多い &\to& 図形が曲線に近づく \end{array}
「二項分布の変化」で
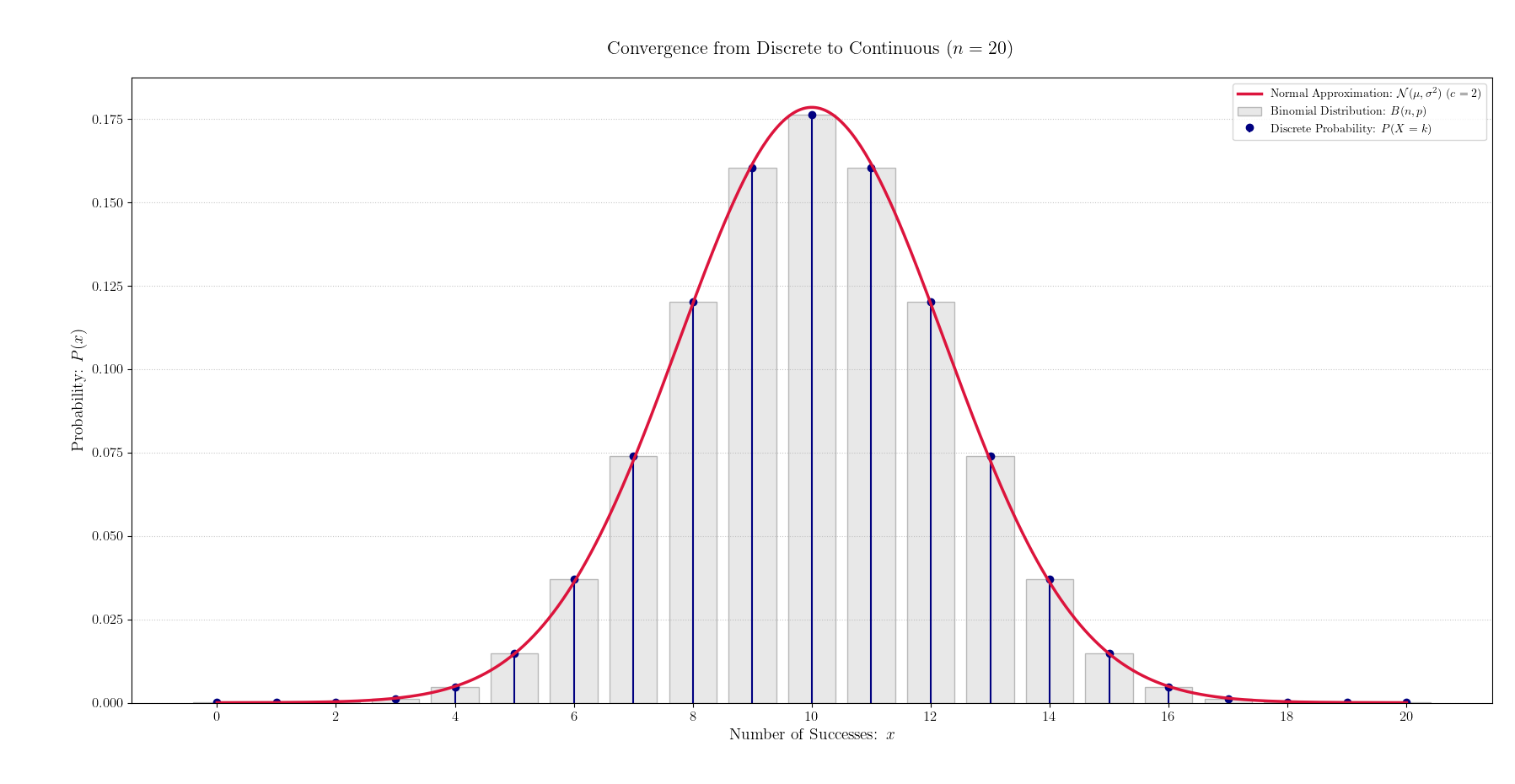
「 n が増えた時の二項分布」の形を考えた時
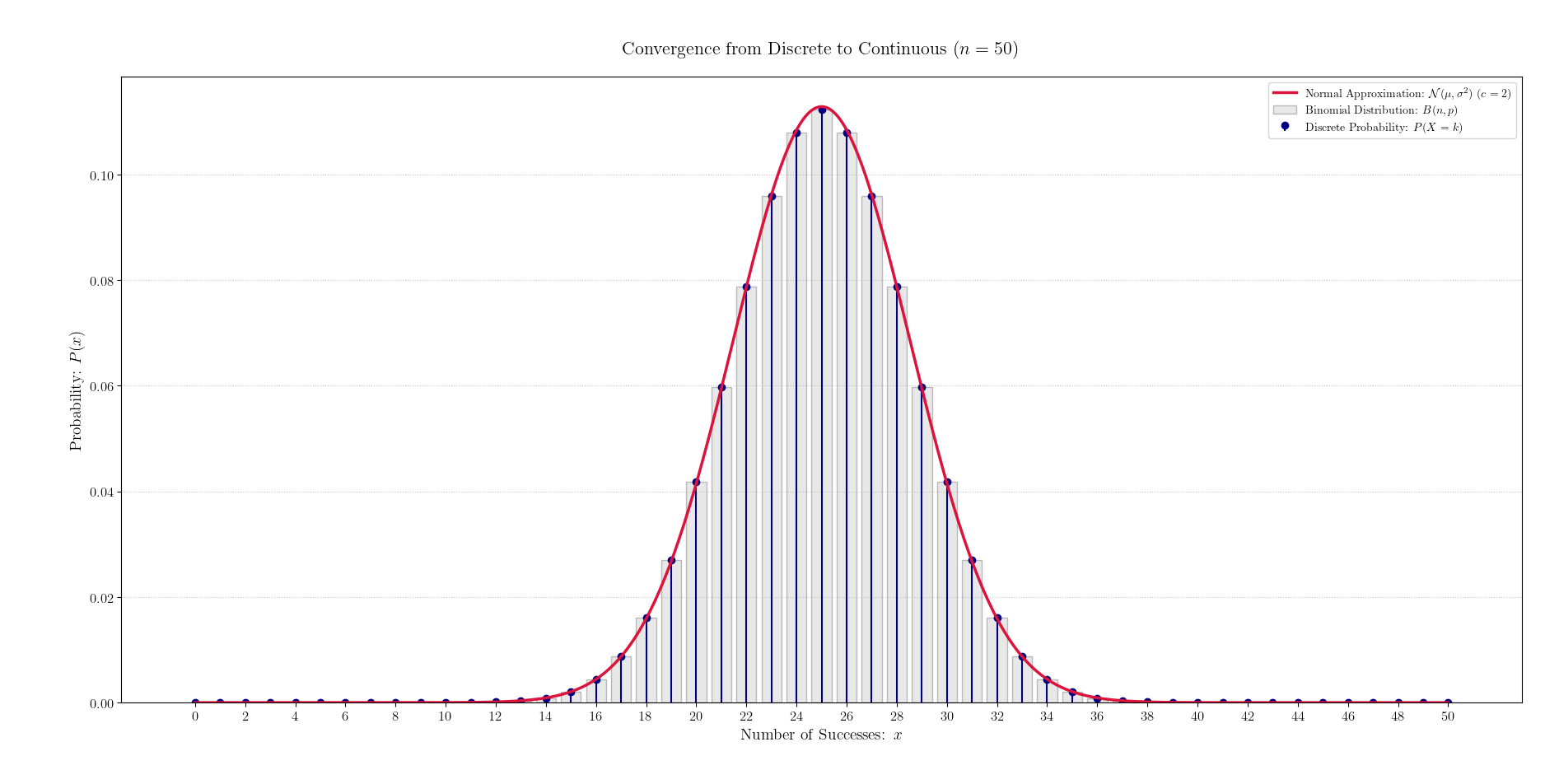
これは N(x) に近づくと考えられることから
\begin{array}{lcl} n=2のx=0 &\to& 端でもあり中心のすぐ傍でもある \\ \\ &\to& 端はx=0で計算もしやすい \\ \\ &\to& すぐ横もx=np\pm 1で計算しやすい \\ \\ \\ 形を合わせたい &\to& 端より中心に近い方を優先したい \\ \\ &\to& (x-np)^2を1にして考えてみる \end{array}
「中心に来ないシンプルな点」を使って考えてみると
\begin{array}{ccl} N(x) &=& \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-np)^2}{cnp(1-p)} } \\ \\ \displaystyle P(np+1) &=& \displaystyle P(np) \cdot e^{\displaystyle -\frac{(np+1-np)^2}{cnp(1-p)} } \end{array}
この時の調整のための値 c が
\begin{array}{lcl} e^{\displaystyle -\frac{(np+1-np)^2}{cnp(1-p)} } &=& e^{\displaystyle -\frac{1}{cnp(1-p)} } \end{array}
ゴリゴリ計算することによって
\begin{array}{lcl} \displaystyle \frac{P(np+1)}{P(np)} &=& \displaystyle \frac{ {}_n \mathrm{C}_{np+1} p^{np+1} (1-p)^{n-(np+1) } }{ {}_n \mathrm{C}_{np} p^{np} (1-p)^{n-np} } \\ \\ &=& \displaystyle \frac{ {}_n \mathrm{C}_{np+1} }{ {}_n \mathrm{C}_{np} } \cdot \frac{ p^{np+1} (1-p)^{n-np-1} }{ p^{np} (1-p)^{n-np} } \\ \\ &=& \displaystyle \frac{ {}_n \mathrm{C}_{np+1} }{ {}_n \mathrm{C}_{np} } \cdot \frac{ p }{ 1-p } \\ \\ &=& \displaystyle \frac{ \frac{n!}{(n-(np+1))!(np+1)!} }{ \frac{n!}{(n-np)!(np)!} } \cdot \frac{ p }{ 1-p } \\ \\ &=& \displaystyle \frac{ n-np }{ np+1 } \cdot \frac{ p }{ 1-p } \\ \\ &=& \displaystyle \frac{np}{np+1} \end{array}
以下の形になんとか整理できるので
\begin{array}{ccccl} \displaystyle P(np+1) &=& \displaystyle P(np) &\cdot & e^{\displaystyle -\frac{(np+1-np)^2}{cnp(1-p)} } \\ \\ \displaystyle \frac{ P(np+1) }{ P(np) } &=& {} && \displaystyle e^{\displaystyle -\frac{(np+1-np)^2}{cnp(1-p)} } \\ \\ \displaystyle \frac{np}{np+1} &=& {} && e^{\displaystyle -\frac{1}{cnp(1-p)} } \end{array}
後はこれを使って
\begin{array}{ccl} \displaystyle p=\frac{1}{2} &\to& \displaystyle \log \frac{n}{n+2} = - \frac{4}{cn} \\ \\ &\to& \displaystyle c=-\frac{4}{n \Bigl( \log n - \log (n+2) \Bigr) } \end{array}
力業で計算すれば
\begin{array}{lclcl} p=\displaystyle \frac{1}{2} & \left\{ \begin{array}{lclcl} n=2 &\to& np=1 &\to& c=2.8853... \\ \\ n=10 &\to& np=5 &\to& c=2.1939... \\ \\ n=20 &\to& np=10 &\to& c=2.0984... \\ \\ n=50 &\to& np=25 &\to& c=2.0397... \\ \\ n=100 &\to& np=50 &\to& c=2.0190... \end{array} \right. \end{array}
「 2 という値が最適」という予想が得られます。
(整数だと計算しやすいというのも理由として大きい)
e^k の定義と 2
知識のある方なら分かると思うんですが
\begin{array}{lcr} \displaystyle c &= & \displaystyle -\frac{4}{n \Bigl( \log n - \log (n+2) \Bigr) } \\ \\ &=& \displaystyle \frac{4}{n \Bigl( \log (n+2) - \log n \Bigr) } \end{array}
この式の分母について観察してみると
\begin{array}{ccl} cの分母 &=& n \Bigl( \log (n+2) - \log n \Bigr) \\ \\ &=& \displaystyle n \left( \log \left( \frac{n+2}{n} \right) \right) \\ \\ &=& \displaystyle n \left( \log \left( 1 + \frac{2}{n} \right) \right) \\ \\ &=& \displaystyle \log \left( 1 + \frac{2}{n} \right)^n \end{array}
これはこのような形になります。
(対数の計算法則はこの記事では省略)
不思議な話ですが
\begin{array}{ccc} e^k &=& \displaystyle \lim_{n\to\infty} \left( 1 + \frac{k}{n} \right)^n \end{array}
この定義の形になるので
n\to\infty という形で「極限」をとれば
\begin{array}{ccc} \displaystyle \lim_{n\to\infty} \log \left( 1 + \frac{2}{n} \right)^n &=& \displaystyle \log e^2 \end{array}
この分母の部分はこのようになります。
(底が e なのでこれは 2 になる)
結果として
\begin{array}{ccc} c &\overset{n\to\infty}{\longrightarrow}& \displaystyle \frac{4}{2} \end{array}
c は 2 という定数に帰結するので
↓ の形は「 n\to\infty の滑らかな二項分布」と
\begin{array}{ccc} \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-np)^2}{2np(1-p)} } \end{array}
『3点では』一致する関数になります。
(山頂とその隣の点はこれと必ず一致する)
端の点と不一致
補足しておくと
\begin{array}{lcl} x=0 &\to& P(0)=(1-p)^n \\ \\ x=0 &\to& \displaystyle N(0)=P(np) \cdot e^{ \displaystyle -\frac{ (0- np)^2 }{cnp(1-p)} } \end{array}
この x=0 での関係と
\begin{array}{lcl} e^{ \displaystyle -\frac{ (0- np)^2 }{cnp(1-p)} } &=&e^{ \displaystyle -\frac{ n^2p^2 }{cnp(1-p)} } \\ \\ &=& e^{ \displaystyle -\frac{ np }{c(1-p)} } \end{array}
この形から得られる
\begin{array}{lcl} P(0) &=& N(0) \\ \\ (1-p)^n &=& \displaystyle P(np) \cdot e^{ \displaystyle -\frac{ np }{c(1-p)} } \\ \\ \displaystyle n\log (1-p) &=& \displaystyle \log P(np) - \frac{ np }{c(1-p)} \end{array}
こちらのパターンからは
\begin{array}{lclcl} p=\displaystyle \frac{1}{2} & \left\{ \begin{array}{lclcl} n=2 &\to& np=1 &\to& c=2.8853... \\ \\ n=10 &\to& np=5 &\to& c=1.8058... \\ \\ n=20 &\to& np=10 &\to& c=1.6491... \\ \\ n=50 &\to& np=25 &\to& c=1.5398... \\ \\ n=100 &\to& np=50 &\to& c=1.4974... \end{array} \right. \end{array}
『一致はしない』という結論が得られます。
(つまり「近似しかできない」という結論が得られる)
一致は無理だが近似は可能
改めて整理すると
\begin{array}{ccc} 事実 & \left\{ \begin{array}{lcl} 求めた形は二項分布に近い \\ \\ 山頂とその隣の点は確実に一致する \\ \\ 端の点は一致しない \end{array} \right. \end{array}
この事実から分かることとして
\begin{array}{ccc} H(x) &=& \displaystyle (調整値) \cdot e^{ \displaystyle -\frac{ (x-μ)^2 }{ 2σ^2 } } \end{array}
「要請」により得られたこの形は
(後に正規分布と呼ばれる形の原型)
\begin{array}{lcl} H(x)の性質 &\to& 二項分布の中心辺りは一致する \\ \\ &\to& 具体的には山頂とその隣の点と一致 \\ \\ &\to& ただし一致するのは n\to\infty の場合 \\ \\ &\to& 有限範囲では確実に一致しない \\ \\ &\to& 端などの極端な点はn\to\infty でも不一致 \\ \\ &\to& H(x)は一致図形ではなく近似図形 \end{array}
あくまで「近似図形」になります。
(中心付近はほぼ一致するが端の点で誤差が出る)
確率を導出するための加工
以上の流れで ↓ の形が得られたわけですが
\begin{array}{ccc} H(x) &=& \displaystyle (調整値) \cdot e^{ \displaystyle -\frac{ (x-μ)^2 }{ 2σ^2 } } \end{array}
これは『単純な分布が持つ性質』の1つである
( H(x) は二項分布と同様の性質を持っていて欲しい)
\begin{array}{ccc} 確率要請 & \left\{ \begin{array}{lcl} データと結びつくものは出現確率 \\ \\ 単純な二項分布もそれに含まれる \\ \\ サンプルであれば全ての分布は同様 \end{array} \right. \end{array}
こういった性質を持っていません。
(サンプル統計であれば確率は 出現回数/データ数 )
離散の点と連続の点で異なる
整理すると
\begin{array}{ccc} \displaystyle P(np) \cdot e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } \end{array}
「二項分布による調整」からも分かるように
( n \to \infty とすると一致するが点は基本的に有限)
\begin{array}{lcl} 1 &=& \cdots +P(np)+ P(np+1)+\cdots \\ \\ 1?&=& \cdots +P(np) \cdot e^{\displaystyle -\frac{(0)^2}{2σ^2} } + P(np+1) \cdot e^{\displaystyle -\frac{(1)^2}{2σ^2} } +\cdots \end{array}
これらは「近い値になるはず」ですが
(図形がかなり近い形になるため)
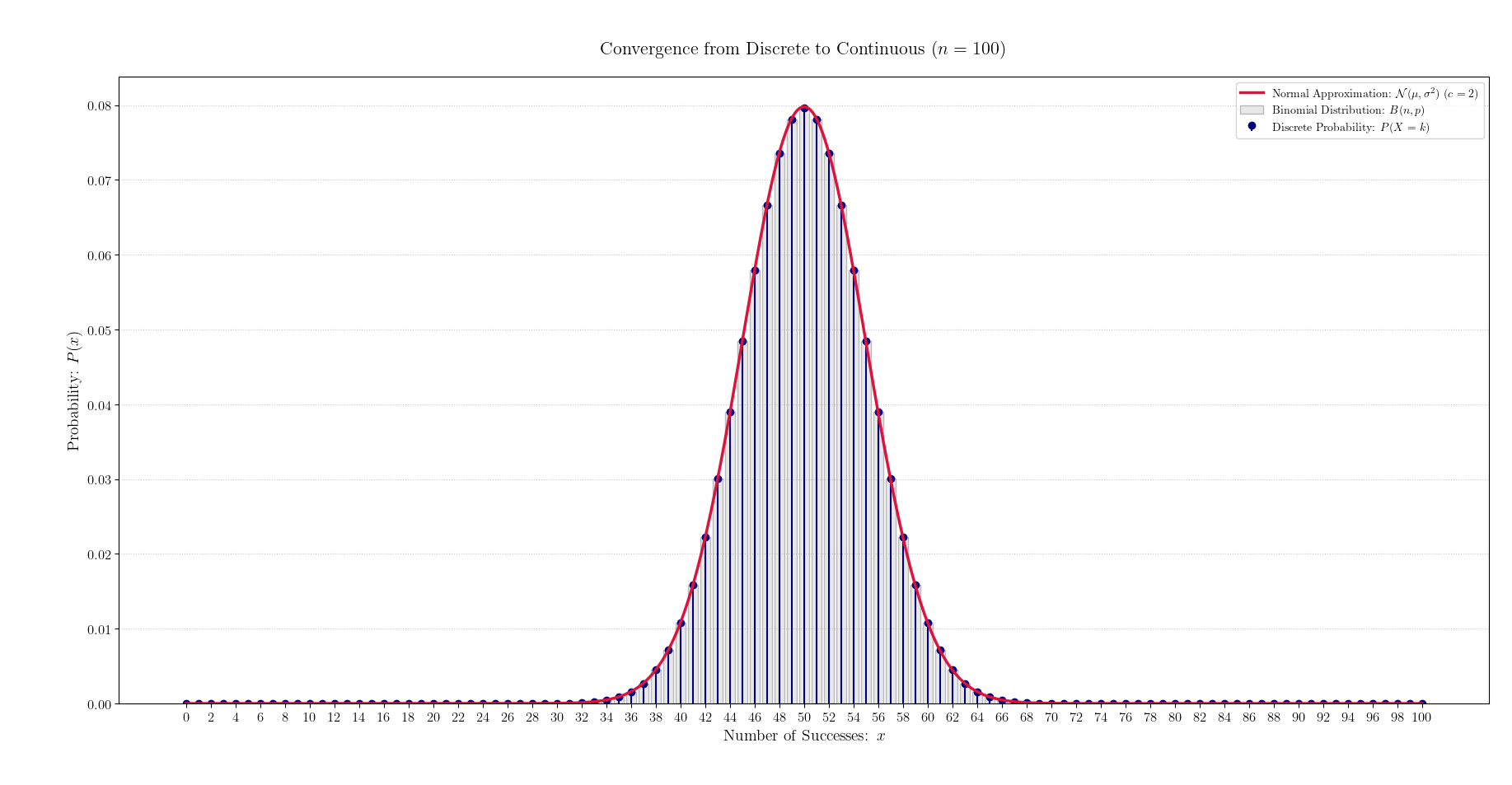
\begin{array}{lcl} np &\to& np+1 \\ \\ x &\to& x+dx \end{array}
これらは「連続」だとほとんど区別できません。
( np と np+1 の間が連続だとほぼ消える)
定数で調整してみる
以上の観察から分かる通り
『連続では隣の点を区別できない』ことから
\begin{array}{lcl} P(np) &>& P(np+1) \\ \\ P(x) &≒& P(x+dx) \end{array}
これらの y の判別ができない。
(極限をとると同じ値になってしまう)
\begin{array}{ccc} P(np) &\to& 似たような定数 \end{array}
また P(np) に縛られず
「一般化したい」という要請から
\begin{array}{ccc} \displaystyle P(np) \cdot e^{\displaystyle -\frac{(k-μ)^2}{2σ^2} } &\to& \displaystyle (調整定数) \cdot e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } \end{array}
「1つの定数で調整したい」という要請が得られます。
(区別できない以上 P(np) は定数にする必要がある)
そして以上の要請から
\begin{array}{ccr} \displaystyle \lim_{n\to\infty} \sum & P(np) \cdot e^{\displaystyle -\frac{(k-μ)^2}{2σ^2} } && 離散 \\ \\ \displaystyle \int_{\infty}^{\infty} & (調整定数) \cdot e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } && 連続 \end{array}
この部分は『 1 にならなければなりません』
(連続パターンに対して確率化要請がかかる)
ガウス積分と都合の良い定数
以上の要請と
\begin{array}{ccc} \displaystyle \int_{-\infty}^{\infty} e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } &=& \displaystyle \sqrt{ \frac{ π }{ \frac{1}{2σ^2} } } \end{array}
この式の積分がこうなることから
(これの詳細はガウス積分の記事で)
\begin{array}{rcc} \displaystyle \int_{\infty}^{\infty} e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } &=& \displaystyle \sqrt{2πσ^2} \end{array}
良い感じの形を『 1 にする』ために
\begin{array}{ccc} \displaystyle \frac{1}{ \sqrt{2πσ^2} } \int_{\infty}^{\infty} e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } &=& 1 \end{array}
これに対してこのような調整が必要になります。
(これでやっと現代の正規分布に一致する)
補足しておくと
「ガウス積分発見前」は
\begin{array}{ccc} 調整値 &=& σ2.5066... \end{array}
「泥臭い計算から」このような形で導かれており
( f(x)(x_2-x_1) は求められるので後は分割を細かくすれば)
\begin{array}{ccc} \displaystyle\sqrt{2π} &≒& 2.5066... \end{array}
この値は丁度この値と近い値になります。
(ガウス積分は特に関数行列なんかがけっこう高度)
スターリングとウォリスの積
補足しておくと
\begin{array}{ccc} \displaystyle\sqrt{2π} &≒& 2.5066... \end{array}
\sqrt{2π} であると特定された経緯は
\begin{array}{ccc} \displaystyle \frac{π}{2} &=& \displaystyle \frac{2}{1} \cdot \frac{2}{3} \cdot\frac{4}{3} \cdot\frac{4}{5} \cdot\frac{6}{5}\cdot\frac{6}{7} \cdots \end{array}
この「ウォリスの積 1655年 」と呼ばれるものを
「スターリング」という人物が知っていたからで
(スターリングの公式はこれを元にしたもの)
\begin{array}{lcl} ドモアブルの相談 &\to& 謎の定数2.5066の正体 \\ \\ スターリングの考察 &\to& \sqrt{2π}に近い値だと分かる \\ \\ 例の関数は近似 &\to& テイラーの予想1715年に存在 \\ \\ &\to& 2次近似で試してみる \\ \\ &\to& スターリングの公式が得られる \end{array}
「根拠は薄い」ながら
(ここまではあくまで実測値の比較でしかない)
\begin{array}{ccc} \displaystyle\sqrt{2π} &≒& 2.5066... \end{array}
『まず間違いなくこうなる』ことは予想されていました。
正規分布の完成
以上をまとめると
\begin{array}{lcl} よく見る形 &\to& 近似の指標が欲しい \\ \\ 形に合わせる &\to& 山のような曲線 \\ \\ 不足を補正 &\to& 実際のデータと比較 \end{array}
この『図形的な要請』と
\begin{array}{lcl} 実際のデータ &\to& 単純なデータが分かり易い \\ \\ 単純なデータ &\to& 二項分布はかなり単純 \\ \\ 形を合わせる &\to& 縦は確率で良いが横が不足 \\ \\ 横が不足する &\to& 横幅を意味する分散を使う \\ \\ まだ横が不足 &\to& 分散だけでは足りない \\ \\ 不足分の値 &\to& 実際のデータと比較する \end{array}
『単純なデータとの整合性』と
\begin{array}{lcl} 二項分布と近い &\to& 形はほとんど一致 \\ \\ 二項分布の性質 &\to& 他の性質も持ってて欲しい \\ \\ 確率化要請 &\to& 確率が持つ性質も欲しい \end{array}
『確率化要請』から得られた ↓ の形が
\begin{array}{rcc} \displaystyle \int_{\infty}^{\infty} \frac{1}{ \sqrt{2πσ^2} } e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } &=& 1 \\ \\ \displaystyle \frac{1}{ \sqrt{2πσ^2} } e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } &=& f(x) \end{array}
「正規分布」と呼ばれる関数になります。
(良い感じの近似図形として調整された成果物)
標準正規分布 Simple
|| 正規分布の中でも一番簡単に扱えるやつ
これは「単純化された正規分布」のことで
\begin{array}{lccl} N(x,μ,σ^2) &=& \displaystyle \frac{1}{ \sqrt{2πσ^2} } & e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } \\ \\ N(x,0,1) &=& \displaystyle \frac{1}{ \sqrt{2π} } & e^{\displaystyle -\frac{x^2}{2} } \end{array}
「関数 N(x,0,1) 」のことを指します。
(正確には x の定義 x\in X も正規分布の定義に含む)
計算の単純化のために変換される形
「単純正規分布」とはつまり『正規分布の雛形』で
\begin{array}{ccc} z&=&\displaystyle \frac{x-μ}{σ} \\ \\ σz+μ &=& x \end{array}
「任意の正規分布」は ↑ の単純な置換によって
( x を中心 μ へ動かして σ^2 で拡大縮小)
\begin{array}{cccl} N(x,μ,σ^2) &=& \displaystyle \frac{1}{ \sqrt{2πσ^2} } & e^{\displaystyle -\frac{(x-μ)^2}{2σ^2} } \\ \\ &=& \displaystyle \frac{1}{ \sqrt{2πσ^2} } & e^{\displaystyle -\frac{z^2}{2} } \\ \\ 確率要請 &\to& \displaystyle \frac{1}{ \sqrt{2π} } & e^{\displaystyle -\frac{z^2}{2} } \end{array}
この形に変形されます。
(これで一律の単純な計算が可能になる)
整理すると
\begin{array}{lcl} 変数整理 &\to& まず中心μへ動かす \\ \\ &\to& σで拡大縮小する \\ \\ \\ 確率要請 &\to& zでの積分値は\sqrt{2π}になる \\ \\ &\to& \sqrt{σ^2}が邪魔になるので取り除く \\ \\ \\ 単純正規分布 &\to& \sqrt{σ^2}を計算結果に掛ける \\ \\ &\to& 変数を\sqrt{σ^2}で拡大縮小しμで動かす \end{array}
このような順番で計算が単純化されます。
(つまり μ と σ さえ求めれば全て計算できる)