
|| 現実における勘違いの元凶その3
『2つのものが影響し合ってる』感覚
スポンサーリンク
目次
相関「2つの何かが連動してる感じ」
相関可能性「2つの何かが連動しているように見える」
無相関「データ分布が散らかってる相関可能性が無い状態」
疑似相関「共通原理で連動している相関ではない関係」
因果関係「ほぼ 100\% の精度の相関の特例」
相関係数「相関を数値で評価する手段」
直線的相関「ピアソンの積率相関係数」
共分散「相関係数で使う考え方の1つ」
情報削減型相関「あえて詳しく見ない感じの相関係数」
単調相関係数「スピアマンの相関係数」
符号多数決相関係数「ケンドールの相関係数」
相関可能性 Correlation Potentiality
|| 連動しているように見えている時点
「相関」と「疑似相関」に分岐する前の状態
\begin{array}{ccc} 相関可能性 A\leftrightarrow B & \left\{ \begin{array}{ll} 疑似相関 & 共通原理が存在 \\ \\ 相関 & 共通原理が未発見 \end{array} \right. \end{array}
「 C\to A,C\to B 」の
『共通原理 C の探索』を行う段階で
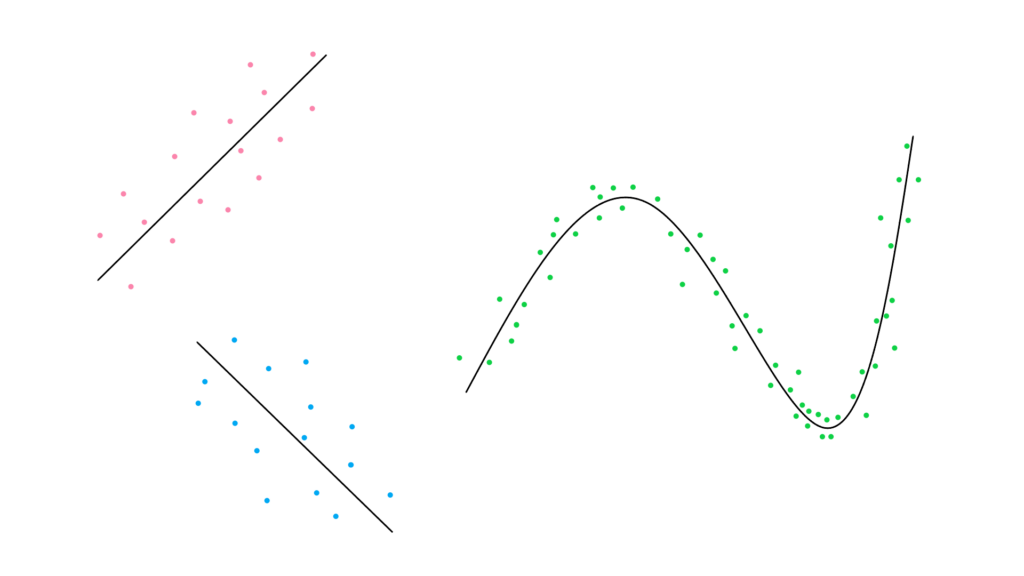
こういったデータ分布が与えれらた段階を指します。
(この時点では相関か疑似相関かはまだ不明)
調査段階と無相関
このさらに前の段階として
\begin{array}{lcl} 調査段階 & \left\{ \begin{array}{ll} 相関可能性 & 相関係数を指標に判断 \\ \\ 無相関 & 同様に相関係数を指標とする \end{array} \right. \end{array}
このような段階があり

こういう「無関係に見える」ような場合では
「無相関」であるとして『相関可能性無し』となります。
(基本的には直感的な相関可能性から始まるのであまり見ない)
疑似相関 Spurious Correlation
|| 相関に見えるが実際には異なる状態
『共通原理』で「相関のように見える」感じ
\begin{array}{ccc} 疑似相関現象 & \left\{ \begin{array}{lcl} 共通原理 &\to& 現象A \\ \\ 共通原理 &\to& 現象B \end{array} \right. \end{array}
「相関ではない」状態であり
(この共通原理が『未発見』の場合が相関)
\begin{array}{lcl} 時計の針 & \left\{ \begin{array}{lcl} 受信による同期 &\to& 電波時計A \\ \\ 受信による同期 &\to& 電波時計B \end{array} \right. \end{array}
具体的にはこういう状態のことを指します。
(時計Aと時計Bの針は連動しているように見える)
因果関係 Causation
|| ほぼ100%連動するという相関の特例
「法則」と呼ばれるほどの相関がある状態
\begin{array}{l} 相関 & \left\{ \begin{array}{ll} 相関関係 & 相関係数が高い \\ \\ 因果関係 & 相関係数が1あるいはほぼ1 \end{array} \right. \end{array}
厳密には後述する「相関係数」で定義でき
\begin{array}{ccc} 因果関係 &\Longleftrightarrow& 相関係数が1の相関関係 \end{array}
結果として『相関関係の1例』になります。
(分離する場合もあるがこの関係の方が現実に整合する)
相関係数 Correlation Coefficient
|| 関係を考察するための比率
「まとまってると高くなる感じ」の比率
\begin{array}{ccl} r&=& \displaystyle \frac{σ_{XY}}{σ_{X}σ_{Y}} \\ \\ &=&\displaystyle \frac{ \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x_{\mathrm{sample}}})(y_i-\overline{y_{\mathrm{sample}}}) }{\displaystyle \sqrt{\frac{1}{n}\sum_{i=1}^{n} (x_i -\overline{x_{\mathrm{sample}}} )^2 }\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i-\overline{y_{\mathrm{sample}}} )^2 } } \end{array}
この「ピアソンの積率相関係数 r 」が基礎になります。
(直線的な相関を評価できる精度の高い基準の1つ)
相関係数への要請
↑ が初見で分かるわけ無いので
まず「相関係数のやりたいこと」について整理します。
\begin{array}{lcl} 相関 & \left\{ \begin{array}{lcl} 相関がある &\to& 値が高い \\ \\ 相関が強い &\to& 高い値になる \\ \\ 相関が弱い &\to& 低い値になる \\ \\ 相関が無い &\to& 値が低い \end{array} \right. \end{array}
そのために『相関係数に求められること』を考えると
それはこんな感じであることが分かり
\begin{array}{lcl} データの観察 &\to& 線上にまとまってる感じ \\ \\ 多くの相関データ &\to& 直線上にまとまってる感じ \\ \\ &\to& 直線を定義する平均が使えそう \\ \\ &\to& 平均とデータの差をとってみる \\ \\ &\to& 分散の考え方に似ている \end{array}
また「データの分布の観察」から
こういう感じであることも分かるので
\begin{array}{lcl} σ_X^2σ_Y^2 が大きい値 &\to& 相関が弱い \\ \\ σ_X^2σ_Y^2 が小さい値 &\to& 相関が強い \end{array}
まずこういう「原始的な指標」を得ることができます。
(分散は平均との差を集めた値なのでこうなる)
\begin{array}{lcl} 相関が強い &\to& 高い値になる \\ \\ 相関が弱い &\to& 低い値になる \end{array}
そしてこの要請から
\begin{array}{lcl} \displaystyle \frac{1}{σ_X^2σ_Y^2} が大きい &\to& 相関が強い \\ \\ \displaystyle \frac{1}{σ_X^2σ_Y^2} が0に近い &\to& 相関が弱い \end{array}
こういった「試行の動機」を得ることもできます。
(相関係数で分散の平方根である標準偏差が来る理由)
比較しやすさについての要請
↑ で導かれた値の観察を行うと
\begin{array}{ccc} 0&<& \displaystyle \frac{1}{σ_X^2σ_Y^2} &<&\infty \end{array}
その「値が取り得る範囲」はこのようになることから
(分散はデータのとり方でも小さくできる)
\begin{array}{lcl} 高い &\to& ある値から見て高い \\ \\ 低い &\to& ある値から見て低い \end{array}
「分かり易い比較」を行うためには
\begin{array}{ccc} 0&<& \displaystyle \frac{?}{σ_X^2σ_Y^2} &<&100 \\ \\ 0&<& \displaystyle \frac{?}{σ_X^2σ_Y^2} &<&1 \end{array}
このような形が望ましいということも予想できます。
(?の部分は分散と連動する値であることも推定できる)
共分散 Covariance
以上を踏まえた上で
\begin{array}{l} 高精度化 & \left\{ \begin{array}{lcl} 基準は維持 &\to& 最大最小は必須 \\ \\ 相関の区別 &\to& 負の値もとりたい \end{array} \right. \end{array}
こういった要請から導かれたのが
(原始的な指標だと分からない部分の追加)
\begin{array}{ccl} \mathrm{Cov}(X,Y) &=& E[(X-μ_X)(Y-μ_Y)] \\ \\ σ_{XY} &= &E[(X-μ_X)(Y-μ_Y)] \\ \\ &=& \displaystyle \frac{1}{n}\sum_{i=1}^{n}(x_i-μ_X)(y_i-μ_Y) \end{array}
この「共分散 \mathrm{Cov} 」と呼ばれる概念になります。
(負の値をとれて標準偏差の概念に近くなる値)
\displaystyle \frac{1}{n} \Bigl( (x_1-μ_X)(y_1-μ_Y)+…+(x_n-μ_X)(y_n-μ_Y) \Bigr)
発生起源からして用途が決まっているので
単体で扱われることはあまりありません。
(これは根本的に要請を満たす都合の良いもの)
上限についての要請
要請を満たせる単純なパターンを考えると
\begin{array}{lcl} 上限の設定 &\to& 割合にしてみる \\ \\ &\to& 1にするなら分散に近い値が必要 \end{array}
この要請から導けるものとして
\begin{array}{ccl} 予想できる形 &\to& そのままだと1になるだけ \\ \\ &\to& 分子は少しずれた値にしたい \\ \\ &\to& 分子は分散の積に近い値 \\ \\ \\ 1以下に &\to& いろいろ考えられる \\ \\ &\to& 分散の積の一部をとってくればいい \\ \\ \\ どの一部? &\to& 分散の2乗の形を考える \\ \\ &\to& a^2+b^2 ≤ (a+b)^2 に繋がる \\ \\ &\to&ベクトルの感覚を使ってみる \\ \\ &\to& 独立同分布などは直交条件 \\ \\ &\to& 相関の調査は独立か不明 \\ \\ &\to& 直交で消えない対角部分 \end{array}
まずこのような形が想定できます。
(共分散の形はこの要請から導かれている)
\begin{array}{c} \displaystyle \frac{1}{n^2}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2(y_i- \overline{y_{\mathrm{sample}}} )^2 \end{array}
そしてその予想できる形の1つとして
このような形を想定することが可能です。
(あくまで考えられる代表的な可能性の1つ)
上限の確認と指標として使えるか
確認しておくと
\begin{array}{ccc} \displaystyle \frac{ \displaystyle \frac{1}{n^2}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2(y_i- \overline{y_{\mathrm{sample}}} )^2 }{ \displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2 \right)\left( \frac{1}{n}\sum_{i=1}^{n} (y_i- \overline{y_{\mathrm{sample}}} )^2 \right) } \end{array}
良さそうなこの形は
\begin{array}{ccc} 0≤a,b &\to& \displaystyle \frac{ a_1b_1 }{ a_1b_1 } = 1 && n=1 \\ \\ 0≤a,b &\to& \displaystyle \frac{ a_1b_1+a_2b_2 }{ a_1b_1+a_1b_2+a_2b_1+a_2b_2 } ≤1 && n=2 \\ \\ && \vdots \end{array}
『下の積の方が余計な値を含む』ので
(上の分子は「対角のもの (a_ib_i)^2 だけ」になる)
\begin{array}{ccc} 0 &≤& \displaystyle \frac{ \displaystyle \frac{1}{n^2}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2(y_i- \overline{y_{\mathrm{sample}}} )^2 }{ \displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2 \right)\left( \frac{1}{n}\sum_{i=1}^{n} (y_i- \overline{y_{\mathrm{sample}}} )^2 \right) } &≤& 1 \end{array}
まずこうなるのは確実です。
(これは単純な不等式と数学的帰納法で確認できる)
『相関の強弱を意味する指標』として機能するか
これについてはちょっと難しいですが
\begin{array}{lcl} 相関評価 &\to& 要請を満たす式が得られる \\ \\ &\to& 必ず分母は分子以上の値になる \\ \\ &\to& 分散が大きい→分子と分母の差が大きい \\ \\ &\to& 分散が小さい→分子と分母の差が小さい \\ \\ &\to& データ量で精度を上げられる \end{array}
「論理的に分かるのは」ここまでで
(これは要請と式の形を読み取った当然の結論)
\begin{array}{lcl} 実際に検証 &\to& 見た目に相関の強い分布 \\ \\ &\to& 1に近い値になった \\ \\ &\to& 見た目に相関が弱い分布 \\ \\ &\to& 0に近い値になった \\ \\ &\to& 評価指標として使える \end{array}
後は『実際に使ってみた結果』が重視されます。
(ここは実際の感覚と整合するか検証が必要な領域)
相関を区別したいという要請
結論から行くと
\begin{array}{ccl} r&=& \displaystyle \frac{σ_{XY}}{σ_{X}σ_{Y}} \\ \\ &=&\displaystyle \frac{ \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x_{\mathrm{sample}}})(y_i-\overline{y_{\mathrm{sample}}}) }{\displaystyle \sqrt{\frac{1}{n}\sum_{i=1}^{n} (x_i -\overline{x_{\mathrm{sample}}} )^2 }\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i-\overline{y_{\mathrm{sample}}} )^2 } } \end{array}
この「ピアソンの相関係数 r 」は
\begin{array}{ccc} \displaystyle \frac{ \displaystyle \frac{1}{n^2}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2(y_i- \overline{y_{\mathrm{sample}}} )^2 }{ \displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} (x_i- \overline{x_{\mathrm{sample}}} )^2 \right)\left( \frac{1}{n}\sum_{i=1}^{n} (y_i- \overline{y_{\mathrm{sample}}} )^2 \right) } \end{array}
↑ の評価指標に ↓ の要請を与えたもので
\begin{array}{lcl} 情報付加 &\to& 正負の相関の区別ができそう \\ \\ &\to& 2乗から1乗にすればできる? \\ \\ &\to& 0<x→0<yなら正でy<0なら負 \\ \\ &\to& 次元合わせで分母を標準偏差に \\ \\ &\to& 実際に計算してみる \\ \\ &\to& 良い感じだった \end{array}
「共分散」という概念は
\begin{array}{lcl} 分子の形 &\to& あらゆる要請を満たす \\ \\ &\to& 共分散と呼ぶことにする \end{array}
「事後的に」整理された産物になります。
(つまり共分散は要請を満たした結果出てくる形の1つ)
情報削減型相関係数 Abstract
|| 情報を削減したからこそ分かること
「直線的相関ではカバーできない範囲」を扱える
\begin{array}{ccl} ρ &=& \displaystyle 1 - \frac{\displaystyle \frac{1}{n}\sum_{i=1}^{n} (データのズレ)_i^2 }{\displaystyle \frac{1}{6}(n-1)(n+1) } \\ \\ \\ τ &=& \displaystyle \frac{(符号一致ペア数)-(符号不一致ペア数)}{{}_n \mathrm{C}_2 } \end{array}
これはそういう「良い感じの相関係数」です。
(大まかに見るから見えることがある感じ)
直線以外も考えたいという要請
『局所的な切り取り』ができれば
\begin{array}{ccl} 直線 &\to& 曲線の一部も拡大すれば直線 \\ \\ &\to& 直線以外の相関もそのようになる \\ \\ &\to& 一部を拡大すれば直線で調査可能 \end{array}
「直線的な相関」で全て説明できますが
(あらゆる相関は膨大な局所相関の集まり)
\begin{array}{lcl} 相関 &\to& 直線ではない相関 \\ \\ &\to& この時点だといつ分かる? \\ \\ &\to& 分からなければ直線に分解できない \\ \\ &\to& 分解したとしてもその後が大変 \\ \\ &\to& 膨大な直線相関を扱うことになる \end{array}
これは『事後的な整理』である上に
「調査が非常に大変」な操作です。
どうにか簡単にできないか
以上の観察から得られた要請
\begin{array}{lcl} よく見る形 &\to& 直線と指数関数と対数関数の形 \\ \\ &\to& これらは図形的に似ている部分がある \\ \\ &\to& それを共通点として取り出せるはず \end{array}
その要請から見えてくる
\begin{array}{lcl} 直線 &\to& xが増えると一定の速度でyが上昇 \\ \\ 指数関数 &\to& xが増えると加速しながらyが上昇 \\ \\ 対数関数 &\to& xが増えると減速しながらyが上昇 \end{array}
「違い」を取り除いた結果として得られたのが
(負の相関のパターンでも y はいずれも減少する)
\begin{array}{lcl} 上昇(共通点) &\to& 加速度だけ異なる \\ \\ &\to& 加速度を考えないとする \\ \\ &\to& xの増加でyも増加する \\ \\ &\to& 加速の仕方はなんでもいい \\ \\ &\to& 加速して減速していても良い \\ \\ &\to& これが共通部分として取り出せる \end{array}
後に「単調相関係数」と呼ばれるものになります。
(増加あるいは減少の大まかな形をカバーできる)
単調相関係数 Spearman
|| 増加と減少の単調性を使った抽象的な相関係数
『増加(あるいは減少)だけで考える相関係数』のこと
\begin{array}{ccc} ρ &=& 1- \displaystyle \frac{\displaystyle \frac{1}{n}\sum_{i=1}^{n} (データのズレ)_i^2 }{\displaystyle \frac{1}{6}(n-1)(n+1) } \end{array}
これは上記の要請から導かれたもので
\begin{array}{ccl} 要請の具体化 &\to& x,yのペアをとる \\ \\ &\to& xの大きさでソートする \\ \\ &\to& xがインデックスとして機能する \\ \\ &\to& インデックス\{1,2,3,...,n\}に変換する \\ \\ \\ yも同様に &\to& yも大小関係でソート \\ \\ &\to& ソート後のyをインデックスに変換する \end{array}
ここから更にこのような要請を得て
( x,y は全て \{1,2,3,...,n\} に変換される)
\begin{array}{ccl} (x,y)の変換 &\to& xを大小関係でインデックスに \\ \\ &\to& yを大小関係でインデックスに \\ \\ \\ 直線評価 &\to& これをピアソンの相関係数で評価 \\ \\ &\to& y_i≤y_{i+1} ならy_{n+1}=y_i +1 になって欲しい \\ \\ &\to& 単調増加ならxの再ソートでy=xに \\ \\ &\to& 単調減少ならxの再ソートでy=1-xに \end{array}
このように具体化することで
「単調相関係数」は導くことができます。
(データの数値を増減の評価で抽象化している)
具体的な単調相関係数の導出
これは見て分かる通り
\begin{array}{lcl} 手順 &\to& データのペア(x,y)で整理 \\ \\ &\to& xを大小関係でソート \\ \\ &\to& xをインデックスに置き換える \\ \\ &\to& データが (i_x,y) に変換される \\ \\ &\to& yを大小関係でソート \\ \\ &\to& yをインデックスに置き換える \\ \\ &\to& データが (i_x,i_y) に変換される \\ \\ &\to& xで再ソート後ピアソンの式へ \end{array}
『データの変換』がメインなので
( (1,1),(2,3),(3,2),... こういう感じになる)
\begin{array}{ccc} ρ &=& 1-\displaystyle \frac{\displaystyle \frac{1}{n}\sum_{i=1}^{n} (データのズレ)_i^2 }{\displaystyle \frac{1}{6}(n-1)(n+1) } \end{array}
これはおまけのようなものなんですが
(整理後の結果なので本質的なものではない)
\begin{array}{lcl} \overline{x} &\to& \displaystyle \frac{1}{n} \Bigl( 1+2+\cdots +n \Bigr) &=& \displaystyle \frac{1}{n} \cdot \frac{1}{2}n(n+1) \\ \\ \overline{y} &\to& \displaystyle \frac{1}{n} \Bigl( 1+2+\cdots +n \Bigr) &=& \displaystyle \frac{1}{n} \cdot \frac{1}{2}n(n+1) \end{array}
これでだいぶ整理できるため紹介しておきます。
(具体的な数値ではなくインデックスの話になる)
直線的相関とインデックスの相関
まず整理しておくと
\begin{array}{ccl} r &=&\displaystyle \frac{ \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y}) }{\displaystyle \sqrt{\frac{1}{n}\sum_{i=1}^{n} (x_i -\overline{x} )^2 }\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i-\overline{y} )^2 } } \end{array}
「直線的な相関」はこうです。
(変換したデータをこれで評価する)
\begin{array}{lcl} \displaystyle \frac{1}{n}\sum_{i=1}^{n} (x_i -\overline{x} )^2 &=& \displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} x_i^2 \right) - \overline{x}^2 \end{array}
そして「分散」はこのように変形できますから
( x_i\overline{x} の総和が平均の2乗になるため)
\begin{array}{lcl} \displaystyle \sum_{k=1}^{n} k &=& \displaystyle \frac{1}{2}n(n+1) \\ \\ \displaystyle \sum_{k=1}^{n} k^2 &=& \displaystyle \frac{1}{6}n(n+1)(2n+1) \end{array}
使う道具を整理して適用すると
\begin{array}{lcl} \displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} x_i^2 \right) - \overline{x}^2 &=& \displaystyle \left( \frac{1}{6}(n+1)(2n+1) \right) - \left( \frac{1}{2}(n+1) \right)^2 \\ \\ &=& \displaystyle (n+1) \left( \frac{1}{6}(2n+1) - \frac{1}{4}(n+1) \right) \\ \\ &=& \displaystyle (n+1)\frac{(n-1)}{12} \end{array}
まず分母はこのように整理されます。
( y もインデックスなので x と同じ結果に)
分子の整理とデータのズレ
以上の整理から
\begin{array}{ccc} \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y}) \end{array}
後はこれを整理すれば良いだけですが
\begin{array}{ccc} (x_i-\overline{x})(y_i-\overline{y}) &=& x_iy_i-x_i\overline{y}-\overline{x}y_i +\overline{x}\overline{y} \end{array}
この式からも分かる通り
\begin{array}{ccc} 分からん &&総和なら && 総和なら && 分かる \\ \\ x_iy_i &-&x_i\overline{y}&-&\overline{x}y_i &+ &\overline{x}\overline{y} \end{array}
1か所だけうまく整理できません。
(ここは総和を考えてもよく分からない)
\begin{array}{lcl} x_iy_iが不明 &\to& 意味はなんとなく分かる \\ \\ &\to& 単調増加なら1になる値 \\ \\ \\ 式の整理 &\to& このままだと計算が大変なまま \\ \\ &\to& これをうまく処理したい \\ \\ &\to& 処理するための何かを考える \end{array}
なのでこういった要請が考えられて
\begin{array}{lcl} 指標が欲しい &\to& 式の意味を考えてみる \\ \\ &\to& 分子は共分散的な何か \\ \\ &\to& 一種の指標が来ると考えられる \\ \\ \\ 原型を参考に &\to& 分散的な感覚が理想のはず \\ \\ &\to& 単調相関係数が見る指標とは \\ \\ &\to& ソートは終わっている \\ \\ \\ 図の観察 &\to& 直線になる場合は? \\ \\ &\to& x_iとy_iが一致している \\ \\ &\to& 不一致の結果どうなるか \\ \\ &\to& x_iとy_iの値がズレている \end{array}
そこから導かれる可能性の1つとして
\begin{array}{lcl} ズレの蓄積 &\to& 単純に考える \\ \\ &\to& (x_i-y_i)^2この分散が来る? \end{array}
このような形が予想として導かれる。
(この時点ではまだうまくいく保証は無い)
\begin{array}{ccl} (x_i-y_i)^2 &=& x^2_i-2x_iy_i+y^2_i \\ \\ 2x_iy_i &=& x^2_i+y^2_i -(x_i-y_i)^2 \end{array}
その結果として
\begin{array}{lcl} \displaystyle \frac{1}{n} \sum_{i=1}^{n}x_iy_i &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} \frac{1}{2} \Bigl( x^2_i+y^2_i -(x_i-y_i)^2 \Bigr) \end{array}
このような式変形が行われ
\begin{array}{ccc} データのズレ &\Longleftrightarrow& d_i=x_i-y_i \end{array}
この部分が『データのズレ』として定義できます。
(この相関係数の分散的な指標に当たる)
スピアマンの相関係数
以上を用いて整理してみると
\begin{array}{lcccccl} \displaystyle \frac{1}{n} \sum_{i=1}^{n} x_i &=& \overline{x} &=& \overline{y} &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} y_i \\ \\ \displaystyle \frac{1}{n} \sum_{i=1}^{n} x_i^2 &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} i^2 &=&\displaystyle \frac{1}{n} \sum_{i=1}^{n} i^2&=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} y_i^2 \end{array}
スピアマンの整理ではこうなるので
(これらは両方インデックスだから成立する)
\begin{array}{ccl} \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y}) &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n}(x_iy_i-x_i\overline{y}-\overline{x}y_i +\overline{x}\overline{y}) \\ \\ &=& \displaystyle \frac{1}{n} \left( \sum_{i=1}^{n}x_iy_i \right) - \overline{x}^2 \end{array}
これはこうなって
\begin{array}{lcl} \displaystyle \frac{1}{n} \sum_{i=1}^{n}x_iy_i &=& \displaystyle \frac{1}{n} \sum_{i=1}^{n} \frac{1}{2} \Bigl( x_i^2+y_i^2-(x_i-y_i)^2 \Bigr) \\ \\ &=& \displaystyle \left( \frac{1}{n} \sum_{i=1}^{n}x_i^2 \right) - \left( \frac{1}{2}\cdot \frac{1}{n} \sum_{i=1}^{n}(x_i-y_i)^2 \right) \end{array}
この部分がうまい具合にこうなるので
\begin{array}{ccc} ρ &=&\displaystyle \frac{ \displaystyle \frac{1}{n} \sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y}) }{\displaystyle \sqrt{\frac{1}{n}\sum_{i=1}^{n} (x_i -\overline{x} )^2 }\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i-\overline{y} )^2 } } \\ \\ &=& \displaystyle \frac{ \displaystyle \left( \frac{1}{n} \sum_{i=1}^{n}x_i^2 \right) -\overline{x}^2 - \left( \frac{1}{2}\cdot \frac{1}{n} \sum_{i=1}^{n}(x_i-y_i)^2 \right) }{\displaystyle \left( \frac{1}{n}\sum_{i=1}^{n} x_i^2 \right) -\overline{x}^2 } \\ \\ &=& 1 - \displaystyle \frac{ \displaystyle \frac{1}{2}\cdot \frac{1}{n} \sum_{i=1}^{n}d_i^2 }{ \displaystyle \frac{1}{12}(n+1)(n-1)} \end{array}
結果、この形を得ることができます。
(これが後にスピアマンの相関係数と呼ばれる)
符号多数決相関係数 Kendall
|| 増えたか減ったかそのままか
「 x が変わった時 y がどうなるか」だけ見る
\begin{array}{lcl} τ &=& \displaystyle \frac{ (符号一致ペア数)-(符号不一致ペア数) }{ {}_n \mathrm{C}_2 } \end{array}
これはスピアマンの要請と途中までは同じで
(単調増加や単調減少に注目するところまで)
\begin{array}{ccl} ソート可能? &\to& x,yのペアはデータをとる段階で確定 \\ \\ &\to& ソートはまだできるか不明 \\ \\ &\to& スピアマンのyをソートしない場合 \\ \\ &\to& xは増加が分かるとする \\ \\ \\ yの増減 &\to& xの増加でyがどう変化するか分かる \\ \\ &\to& yの数値は考えず変化したかだけ \\ \\ &\to& 増えるなら1を返すとする \\ \\ &\to& 変化しないなら0 \\ \\ &\to& 減るなら-1を返す \end{array}
ここから『 x のソートも排除』したものが
\begin{array}{lcl} ソート無し &\to& xの比較は好きに行える \\ \\ &\to& y同様にx_j-x_iで比較してみる \\ \\ \\ 0<x_j-x_iの場合 &\to& y_jとy_iの比較で+,0,-に分岐 \\ \\ &\to& 0<y_j-y_i なら単調増加 \\ \\ &\to& 他も同様に分かる \end{array}
「ケンドールの相関係数」と呼ばれるものになります。
(つまりスピアマンとはアプローチが根本的に異なる)
比較と符号
これは最初の部分だけ分かり辛いですが
\begin{array}{lcl} 単調増加 & \left\{ \begin{array}{lcl} x_i≤x_j &\to& y_i≤y_j \\ \\ x_i≥x_j &\to& y_i≥y_j \end{array} \right. \end{array}
このような共通点となるデータの観察から
『符号の一致』という指標が得られるので
(一致する場合には必ず単調増加になる)
\begin{array}{ccc} \mathrm{sign}(x) &=& \left\{ \begin{array}{rcl} 1 && 0<x \\ \\ 0 &&x=0 \\ \\ -1 && x<0 \end{array} \right. \end{array}
「符号関数 \mathrm{sign} 」を用いることで
\begin{array}{ccc} \mathrm{sign} (x_j-x_i) \mathrm{sign} (y_j-y_i) \end{array}
このような形で指標を表現することができます。
(符号のパターンで増加か減少か判定できる)
補足しておくと
\begin{array}{ccccl} \mathrm{sign} (x_j-x_i) && \mathrm{sign} (y_j-y_i) \\ \\ + & \times & + &\to& 増加 \\ \\ - &\times & - &\to& 増加 \\ \\ + & \times & - &\to& 減少 \\ \\ - & \times & + &\to& 減少 \\ \\ \pm &\times & 0 &\to& 変化無し \end{array}
これは感覚的にはこのようになっています。
(本質的にはただ符号 +,- の話をしてるだけ)
多数決と平均
ケンドールの相関係数は
この『符号の一致がどれだけ起きるか』を見ていて
\begin{array}{lcl} 増加したパターンの総数 & - & 減少したパターンの総数 \\ \\ 符号一致パターンの総数 &-& 符号不一致パターンの総数 \end{array}
この「パターン総数の比較」を行った時の
\begin{array}{lcl} 全て増加 &\to& 単調増加 \\ \\ 全て減少 &\to& 単調減少 \\ \\ 0に近い &\to& 増加したり減少したり \end{array}
実際のデータの比較と
\begin{array}{lcl} 比較 &\to& 2つのデータ(x_i,y_i),(x_j,y_j)をとる \\ \\ &\to& n個のデータから2つのデータを選ぶ \\ \\ &\to& {}_n \mathrm{C}_2 パターンの選び方がある \end{array}
『平均』の考え方から
\begin{array}{lcl} τ &=& \displaystyle \frac{ (符号一致ペア数)-(符号不一致ペア数) }{ {}_n \mathrm{C}_2 } \end{array}
この相関係数の形は得られています。
(根本的にただ平均を導いているだけ)